日前,快手方面正式发布新一代视频生成模型可灵 2.6。据了解,这是可灵*音画同出模型,能够在单次生成中输出包含画面,自然语言、动作音效,以及环境氛围音等在内的完整视频,改变了传统 AI 视频生成模型 " 先无声画面、后人工配音 " 的工作流程。
据悉,通过对物理世界声音与动态画面的深度语义对齐,可灵 2.6 在音画协同、音频质量和语义理解上表现亮眼,同时在中文语音生成效果上保持全球领先。以音频质量为例,其在支持人声、音效、环境声等多类型声音生成的基础上,生成的音频音质更干净、层次更丰富,整体听感更接近真实的混音效果,可满足专业级创作对声音细节的要求。
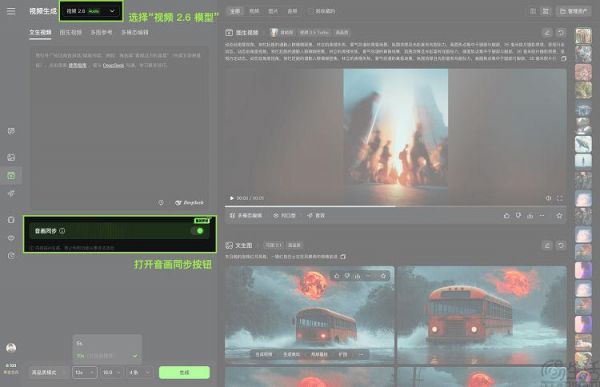
在创作流程上,可灵 2.6 提供文生音画、图生音画 2 条高效创作路径,适配单人独白、旁白解说、多人对白、音乐表演等场景。这就意味着用户不论输入文本或是图片结合文本提示词,均可直接生成音画同步的完整视频。
目前,用户已经可以在可灵 App 与官网体验可灵 2.6,并且会员用户可享标准与高品质模式。
值得一提的是,在不久前举行的 2025 年第三季度财报电话会上,快手创始人兼首席执行官程一笑就曾表示,可灵的愿景非常清晰,那就是 " 让每个人都能用 AI 讲出好故事 ",公司将聚焦于 AI 影视创作这一核心目标,聚合资源深入打磨技术与产品能力。
根据快手方面公布的相关数据数据,预计 2025 年全年可灵的收入将达到 1.4 亿美元,较年初制定的 6000 万美元目标提升超过 100%。
对此快手首席财务官金秉表示,在可灵收入增长与 AI 业务整体进展超预期的背景下,公司正在不断追加算力投入。据悉,鉴于用户对视频生成模型的需求持续增强,快手方面已多次扩充可灵在推理侧的算力。同时随着模型加速迭代,该公司也开始提升训练算力,以保持可灵在技术上的前沿性和竞争力。